- Published on
AI Safety Needs Great Product Builders
- Authors
- Name
- James Brady
- @james_elicit


In his AI Safety Needs Great Engineers post, Andy Jones explains how software engineers can reduce the risks of unfriendly artificial intelligence. Even without deep ML knowledge, these developers can work effectively on the challenges involved in building and understanding large language models.
I would broaden the claim: AI safety doesn’t need only great engineers – it needs great product builders.
This post will describe why, list some concrete projects for a few different roles, and show how they contribute to AI going better for everyone.
Audience
This post is aimed at anyone who has been involved with building software products: web developers, product managers, designers, founders, devops, generalist software engineers, … I’ll call these product builders.
Non-technical roles (e.g. operations, HR, finance) do exist in many organisations focussed on AI safety, but this post isn’t aimed at them.
But I thought I would need a PhD!
In the past, most technical AI safety work was done in academia or in research labs. This is changing because – among other things – we now have concrete ideas for how to construct AI in a safer manner.
However, it’s not enough for us to merely have ideas of what to build. We need teams of people to partner with these researchers and build real systems, in order to:
- Test whether they work in the real world.
- Demonstrate that they have the nice safety features we’re looking for.
- Gather empirical data for future research.
This strand of AI safety work looks much more like product development, which is why you – as a product builder – can have a direct impact today.
Example projects, and why they’re important
To prove there are tangible ways that product builders can contribute to AI safety, I’ll give some current examples of work we’re doing at Ought.
For software engineers
In addition to working on our user-facing app, Elicit, we recently open-sourced our Interactive Composition Explorer (ICE).
ICE is a tool to help us and others better understand Factored Cognition. It consists of a software framework and an interactive visualiser:

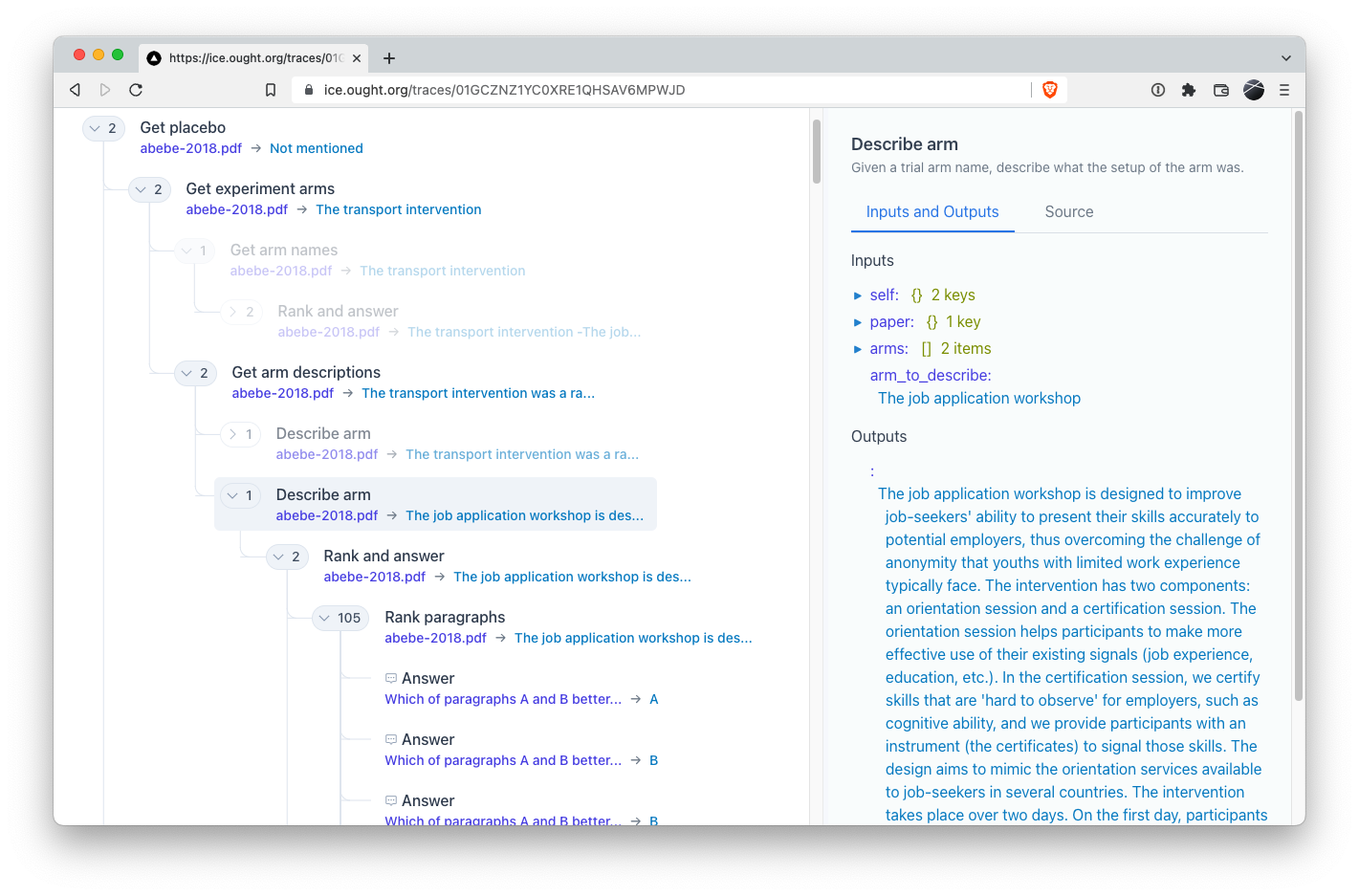
On the back-end, we’re looking for better ways to instrument the cognition “recipes” such that our framework stays out of the user’s way as much as possible, while still giving a useful trace of the reasoning process. We’re using some meta-programming, and having good CS fundamentals would be helpful, but there’s no ML experience required. Plus working on open-source projects is super fun!
If you are more of a front-end developer, you’ll appreciate that representing a complex deductive process is a UX challenge as much as anything else. These execution graphs can be very large, cyclic, oddly and unpredictably shaped, and each node can contain masses of information. How can we present this in a useful UI which captures the macro structure and still allows the user to dive into the minutiae?
This work is important for safety because AI systems that have a legible decision-making process are easier to reason about and more trustworthy. On a more technical level, Factored Cognition looks like it will be a linchpin of Iterated Distillation and Amplification – one of the few concrete suggestions for a safer way to build AI.
For product managers
At first, it might not be obvious how big of an impact product managers can have on AI safety (the same goes for designers). However, interface design is an alignment problem – and it’s even more neglected than other areas of safety research.
You don’t need a super technical background, or to already be steeped in ML. The competing priorities we face every day in our product decisions will be fairly familiar to experienced PMs. Here are some example trade-offs that we regularly navigate for our app, Elicit:
Deliver terse, valuable insights to users
Expose the inner-workings of the system
Follow familiar product paradigms
Users get more immediate value from interfaces which feel familiar.Imagine radical new workflows
Language models offer opportunities for novel interaction styles which might be more valuable in the medium-term.Get users quick answers to their questions
Quick answers let our users power through well-defined tasks.Help users carefully navigate a complex task
Perhaps we offer more lasting value by acting as a reasoning assistant – it certainly better fits our overall mission.Compensate for limitations in today’s language models
Language models have various known limitations, and our current product is valuable to users when we work around those limitations.Build functionality which scales to powerful future models
Limitations are going to retreat and change with every improvement to language models. We want our work to be super-charged by change, rather than deprecated by it.
In my opinion, the main thing which makes product management at Ought different from other places is that we are working on the frontier of new technology. We regularly dream up features which turn out to just not be possible – even using today’s most powerful models1. Our product direction isn’t only informed by our strategy and our users, it’s also influenced by what can be realised on the cutting edge of machine learning.
Great product managers can have an enormous impact on AI safety by helping us find the right balance between:
- Proving our app is useful, and
- Proving our approach is safer
If we lean too much towards adding crowd-pleasing widgets to our product, we won’t make enough progress on our mission to prove out process-based systems. On the other hand, if we lean too much towards researching process-based systems, we will – at best – prove they’re theoretically interesting rather than actually useful.
For infrastructure engineers
Because of the nature of the research we’re doing and the design of the product we’re building, we’re hitting a bunch of different ML APIs to do different jobs in different places.


At the moment, we don’t have the infrastructure to record all of these interactions with 3rd party and internal models. We’d like to insert an abstraction layer between our code and the ML models to achieve a few things:
- The ability to fallback to alternatives when a model goes down or has increased latency (this is still quite common with 3rd party models).
- Build up datasets of task/result pairs, which we can then use to train our own models in the future. These training data would, by their nature, be representative of the queries our users are interested in. We could even enrich the dataset with user feedback from the app: if someone marked one of our answers as “not good”, we can use that to improve the models on the next iteration.
- Enable us to split traffic to a couple of different back-end models, so that we can compare them head-to-head. We’d like to understand how operational metrics like latency, throughput, and error rate compare between different APIs, using real traffic.
Implementing this abstraction layer would be challenging work. Obviously, when running in our production environment performance and reliability is critical. In contrast, for internal experiments we’d like the system to be highly flexible and easy to modify. There are some tools for tracking datasets and versioning, but it’s a relatively immature space compared to conventional infrastructure: there’s not an enormous toolchain for you to learn!
This is a key component of our AI safety work because building up these datasets of task/result pairs is one way to do the “Distillation” part of Iterated Distillation and Amplification. For example, imagine we have a complex and expensive Factored Cognition process running in our infrastructure. After 1000, 10000, or 100000 examples we could hot-swap in a new model trained on the real data captured at your abstraction layer.
Why would you do this?
Hopefully the examples above show that there is a wide range of product building work which can help with AI safety. But there are lots of exciting opportunities out there! What makes this area so special?
Here are some of the things that excite me the most about working on AI safety:
Impactful work
80,000 Hours rates AI safety as one of its highest priority causes because the risks are astronomical, there are tangible things we can do to help, and talent is currently the main constraint.
The people are fantastic
Because it’s a nascent field with an altruistic bent, your colleagues and peers will generally have strong prosocial motivations. They will be gifted, dedicated, interesting team mates who aren’t just doing it for a paycheck.
Talking of paychecks…
Many of the organisations working on AI safety (including Ought!) are well-funded. You can work on something important without needing to sacrifice your creature comforts, or priorities like Earning To Give.
Interesting, challenging work every day
Nowadays, a lot of product development work is highly commoditised. We have enough frameworks, methodologies, tools, and services to make software projects feel like building a Lego set, rather than a truly novel challenge. This is not yet true with AI. New models, architectures, and techniques are being developed all the time, and there’s a tight feedback loop between academia and industry.
In fact, if you fit the profile of the audience of this post, and the points I just made above resonate with you, you might find that AI safety is your Ikigai – I did!


What to do now?
If this post has resonated with you and you’d like to know more about Ought:
- Try our app, Elicit, to better understand what we’re building.
- Go through our Factored Cognition Primer, through which you’ll develop hands-on experience with the approach we’re taking.
- Read Supervise Process, not Outcomes to learn more about the framework within which our work sits.
- Take a look at our open roles!
If you’re interested in working in AI safety more generally:
- Preventing an AI-related catastrophe is a comprehensive and up-to-date overview of the cause area.
- 80,000 Hours also offers 1-1 advice to people looking to move to a high-impact career.
- We’re starting a reading group aimed at the same sorts of people that this post is catered to. You can register your interest here!
My thanks to Jungwon Byun, Andreas Stuhlmüller, Odette Brady, Eric Arellano, Jess Smith, and Maggie Appleton for their contributions to this post.
Footnotes
One recent example: we explored the idea of generating a 1–2 sentence summary of the salient parts from the papers a user has found. Multi-document summarisation turned out to be too complex of a task for the largest language model we have access to: it hallucinated facts and missed or misattributed key details. However, this did spur a flurry of activity to figure out a workaround, and we found that chain-of-thought reasoning can be effective, as can a factored cognition approach. We will be launching a “paragraph synthesis” feature in the next couple of weeks. ↩